| FINANCEBETTING/CASINOSGAMINGSOCIAL/MEDIAMONITORING |  |
| HOME >> TECHNOLOGY >> ARCHITECTURE | |
|
What Is Lightstreamer?
Lightstreamer is a real-time messaging server optimized for the Internet.
Lightstreamer streams data across the Internet, reaching any type of clients (mobile, web, desktop, and IoT) and passing through any kind of proxy and firewall. Blending WebSockets, HTTP, and push notifications, it implements bi-directional communication, while guaranteeing low latency and high scalability. Lightstreamer's state-of-the-art automatic bandwidth throttling continuously adapts the message rate to network capacity.
Lightstreamer's Architecture
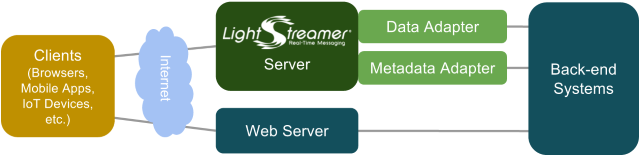
The Lightstreamer Server is a stand-alone process that runs in a Java Virtual Machine (JVM). It handles the connections with the clients and pushes real-time data between the back-end systems and the clients. The Lightstreamer Server runs on both Linux and Windows, supporting both on-premises and cloud-based machines.
The clients get synchronous data from any common web server (pulled data, such as web pages or any request/response interaction) and asynchronous real-time data from the Lightstreamer Server (pushed data). The clients can also send real-time data to the Lightstreamer Server. Many different client APIs are provided out of the box, including JavaScript for Web, Android, iOS, .NET, Node.js, Java SE, Python, Flutter, and many others. In addition, full documentation of the Lightstreamer network protocol (called TLCP) is provided, to enable implementations in any other language. On the server side, the Lightstreamer Adapters are custom components developed using the provided APIs for Java, .NET, Node.js, Python, and TCP sockets. The Data Adapter connects the data feed to the Lightstreamer Server and injects the real-time data flow. The Metadata Adapter manages fine-grained authentication and authorization.  Download Download
Logical Layers ►
|